This final year project focussed on using the OpenMP and MPI frameworks to parallelise an implementation of the straightforward pattern matching algorithm. The project was scored purely on the speed of the solutions (assuming the generated matches were correct), and in the module overall I scored a strong first class mark of 83. I have put the code on my GitHub for your perusal.
Project Specification
The straightforward string matching algorithm simply checks every position in the text to see if the desired pattern occurs starting at that position. The combinations of patterns and texts to test are specified by a control file, which lists the mode, text to use and pattern to use.
There are two modes required: mode 0, in which only the first instance of the pattern is required, and mode 1, in which all instances of the pattern in the text should be found. The results were to be output to a file which specifies, for each test, the text, pattern and index of the pattern match (or -1 if no match found).
Development
I first wrote a sequential version of the solution, using no parallelisation at all. I would use this to generate guaranteed-correct solutions from my test data, and use the time taken to generate these solutions as a baseline for comparison against my parallel solutions.
Once this was complete and I could generate solutions and times for the test data, read in the control file correctly and output the results in the correct format, I moved onto the parallel solutions, reusing file input and output functions and the basic string comparison functionality, but tailoring the operation and flow of each program to match the framework being used.
The OpenMP Solution
The OpenMP solution uses the ease-of-use of OpenMP to its advantage. The operation of finding the pattern is simply put into a parallel for loop, the set up of the solution remaining largely unchanged otherwise. If the solution has already been found and it is running mode 0, it skips the check. Critical sections are in place to ensure that only one thread modifies the ‘found’ flag at once.
Performance
To test the solution, I ran it against some test data and compared its time to the sequential solution I’d written earlier. The test data comprised of two sets of patterns and texts, testing both modes on each combination of text and pattern within the datasets. The first set, A2, gave a bunch of worst case scenarios (the pattern appearing once, at the end of the text) over varying text and pattern sizes. The second set, A3, had a variety of different patterns appearing in different places throughout the text. In addition to this, I had a third data set purely for testing edge cases, but these were so small that the times were unreliable for testing performance.
The results are summarised below:
| Test set | Sequential time taken (seconds) | OpenMP time taken (seconds) |
| A2 | 146.813 | 18.682 |
| A3 | 88.904 | 9.212 |
| Total | 235.717 | 27.894 |
As you can see, the OpenMP solution, using 8 threads, takes much less time to complete than the sequential version does, a very good improvement.
The MPI Solution
The MPI solution is far more involved. I initially explored a solution that simply split the text up so that each process would check one portion of the text; for example, using 16 processes, each process would check 1/16th of the text. The results from this solution were disappointing, however:
| Test set | Sequential time taken (seconds) | OpenMP time taken (seconds) | MPI time taken (seconds) |
| A2 | 146.813 | 18.682 | 23.642 |
| A3 | 88.904 | 9.212 | 21.196 |
| Total | 235.717 | 27.894 | 44.838 |
It’s faster than the sequential version, but much slower than the OpenMP equivalent. I identified a couple of areas for improvement.
Firstly, in mode 0, there could be a case where the solution is found partway through a later segment, but before earlier segments have completed their searches. This is illustrated here:

This also means that later segments have completed work unnecessarily, wasting more time.
When finding all instances of the pattern, there could also be room for improvement; there may be segments where the pattern match fails quickly (where the first character of the pattern doesn’t match the current text position), but other segments where there are a lot of matches (for example, looking for the pattern ‘aaab’ in a text segment of all ‘a’s). The threads who fail quickly will complete their tasks faster than the thread whose segment contains a lot of potential matches, and be forced to wait for that thread to complete, when potentially the work could be split among the other threads:

The solution I came up with was to use a master and slave model, where the master interprets the control file and figures out what jobs need to be done, then sends these jobs off to the slave processes, each of which return the result of their search to the master, who collects all the results and generates the output file. The job sizes can be made much smaller than the big chunks of text that each process had before, adding a much finer granularity to the solution, and bypassing both flaws with the first solution. The idea is demonstrated here:

Performance
After completing the program I used the same test data as before to tune the job size (the number of text positions the master will give each slave to check in a single job) to a quantity that allowed the master and slaves to work together efficiently (as having too small a job size would put too much pressure on the master, undoing any benefit from parallelisation, but too large a job size would just recreate the problems listed above). The results from that test are shown in this graph:
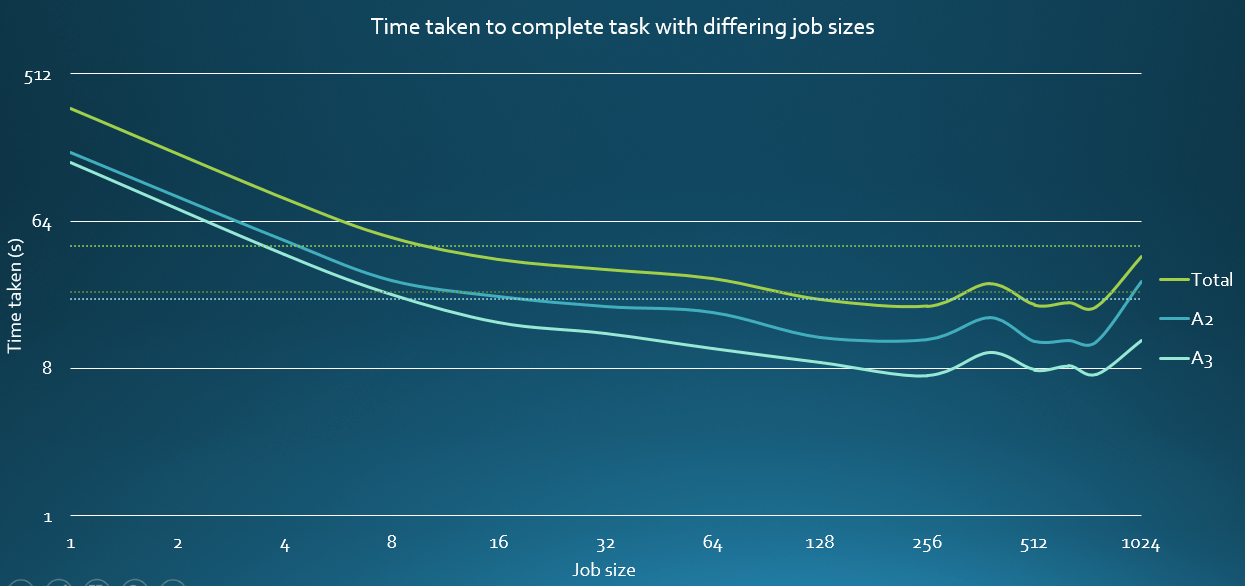
From these tests I ended up using a job size of 768, which was the fastest by half a second.
Compared to the other solutions, the new MPI solution performs as thus:
| Test set | Sequential time taken (seconds) | OpenMP time taken (seconds) | MPI (old) time taken (seconds) | MPI time taken (seconds) |
| A2 | 146.813 | 18.682 | 23.642 | 11.717 |
| A3 | 88.904 | 9.212 | 21.196 | 7.358 |
| Total | 235.717 | 27.894 | 44.838 | 19.075 |
The new solution blows the old one, and even the OpenMP solution, out of the water for this data.
Improvements
The time could be improved even more, however. In the current solution, the master must wait for every slave to complete its job on the current task before moving onto the next text and pattern. If I modified the master to keep track of which results have been returned and collate them once all results for a single test have been returned, it could potentially send out new jobs for the next test to other slaves while the slaves working on the previous task continue their work. This would reduce the time even further. The only reason I did not implement this is that I ran out of time. But it is a viable avenue to explore and will certainly speed the solution up even further.
Conclusion
I was very pleased with the times I got in the end, and my programs came through for the assessment, returning the correct results in short times for a previously unseen set of data. I learnt a lot from using OpenMP and MPI. Out of the two, I’d say OpenMP is easier to grasp, practically and conceptually, and it was very easy to write a decent solution for the problem. However, MPI allows a level of flexibility that, depending on how the developer utilises it, can give some very impressive results.